CoarseGrainedExecutorBackend¶
decommissionSelf¶
decommissionSelf(): Unit
decommissionSelf...FIXME
decommissionSelf is used when:
CoarseGrainedExecutorBackendis requested to handle a DecommissionExecutor message
Messages¶
DecommissionExecutor¶
DecommissionExecutor is sent out when CoarseGrainedSchedulerBackend is requested to decommissionExecutors
When received, CoarseGrainedExecutorBackend decommissionSelf.
Review Me¶
CoarseGrainedExecutorBackend is an executor:ExecutorBackend.md[] that controls the lifecycle of a single <
.CoarseGrainedExecutorBackend Sending Task Status Updates to Driver's CoarseGrainedScheduler Endpoint image::CoarseGrainedExecutorBackend-statusUpdate.png[align="center"]
CoarseGrainedExecutorBackend is a rpc:RpcEndpoint.md#ThreadSafeRpcEndpoint[ThreadSafeRpcEndpoint] that <
CoarseGrainedExecutorBackend is started in a resource container (as a <
When <
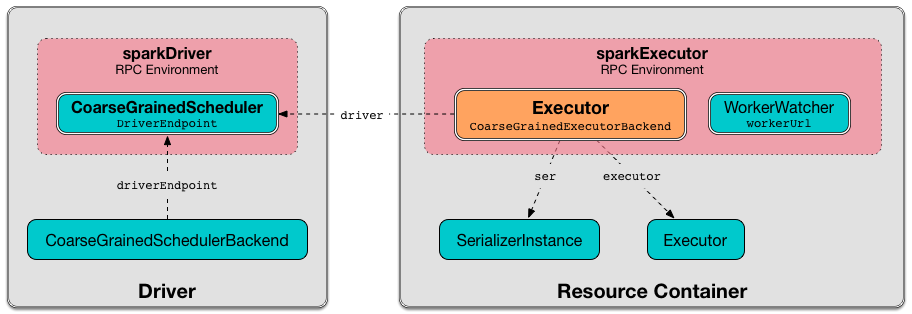
When <
[[messages]] .CoarseGrainedExecutorBackend's RPC Messages [width="100%",cols="1,2",options="header"] |=== | Message | Description
| < |
|---|
| <
| <
Sent exclusively when CoarseGrainedSchedulerBackend scheduler:CoarseGrainedSchedulerBackend.md#RegisterExecutor[receives RegisterExecutor].
| < |
|---|
| < |
|---|
| < |
|---|
|===
== [[LaunchTask]] Forwarding Launch Task Request to Executor (from Driver) -- LaunchTask Message Handler
[source, scala]¶
LaunchTask(data: SerializableBuffer) extends CoarseGrainedClusterMessage¶
NOTE: CoarseGrainedExecutorBackend acts as a proxy between the driver and the managed single <LaunchTask payload (as serialized data) to pass it along for execution.
LaunchTask first decodes TaskDescription from data. You should see the following INFO message in the logs:
INFO CoarseGrainedExecutorBackend: Got assigned task [id]
LaunchTask then executor:Executor.md#launchTask[launches the task on the executor] (passing itself as the owning executor:ExecutorBackend.md[] and decoded TaskDescription).
If <LaunchTask <1 and ExecutorLossReason with the following message:
Received LaunchTask command but executor was null
NOTE: LaunchTask is sent when CoarseGrainedSchedulerBackend is requested to launch tasks (one LaunchTask per task).
== [[statusUpdate]] Sending Task Status Updates to Driver -- statusUpdate Method
[source, scala]¶
statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer): Unit¶
NOTE: statusUpdate is part of executor:ExecutorBackend.md#statusUpdate[ExecutorBackend Contract] to send task status updates to a scheduler (on the driver).
statusUpdate creates a StatusUpdate (with the input taskId, state, and data together with the <
.CoarseGrainedExecutorBackend Sending Task Status Updates to Driver's CoarseGrainedScheduler Endpoint image::CoarseGrainedExecutorBackend-statusUpdate.png[align="center"]
When no <
WARN Drop [msg] because has not yet connected to driver
== [[driverURL]] Driver's URL
The driver's URL is of the format spark://[RpcEndpoint name]@[hostname]:[port], e.g. spark://CoarseGrainedScheduler@192.168.1.6:64859.
== [[main]] Launching CoarseGrainedExecutorBackend Standalone Application (in Resource Container)
CoarseGrainedExecutorBackend is a standalone application (i.e. comes with main entry method) that parses <
[[command-line-arguments]] .CoarseGrainedExecutorBackend Command-Line Arguments [cols="1,^1,2",options="header",width="100%"] |=== | Argument | Required? | Description
| [[driver-url]] --driver-url | yes | Driver's URL. See <
| [[executor-id]] --executor-id | yes | Executor id
| [[hostname]] --hostname | yes | Host name
| [[cores]] --cores | yes | Number of cores (that must be greater than 0).
| [[app-id]] --app-id | yes | Application id
| [[worker-url]] --worker-url | no | Worker's URL, e.g. spark://Worker@192.168.1.6:64557
NOTE: --worker-url is only used in spark-standalone-StandaloneSchedulerBackend.md[Spark Standalone] to enforce fate-sharing with the worker.
| [[user-class-path]] --user-class-path | no | User-defined class path entry which can be an URL or path to a resource (often a jar file) to be added to CLASSPATH; can be specified multiple times.
|===
When executed with unrecognized command-line arguments or required arguments are missing, main shows the usage help and exits (with exit status 1).
[source]¶
$ ./bin/spark-class org.apache.spark.executor.CoarseGrainedExecutorBackend
Usage: CoarseGrainedExecutorBackend [options]
Options are: --driver-url
main is used when:
-
(Spark Standalone) StandaloneSchedulerBackend is requested to spark-standalone:StandaloneSchedulerBackend.md#start[start]
-
(Spark on YARN) ExecutorRunnable is requested to spark-on-yarn:spark-yarn-ExecutorRunnable.md#run[start] (in a YARN resource container).
-
(Spark on Mesos) MesosCoarseGrainedSchedulerBackend is requested to spark-on-mesos:spark-mesos-MesosCoarseGrainedSchedulerBackend.md#createCommand[launch Spark executors]
== [[run]] Starting CoarseGrainedExecutorBackend
[source, scala]¶
run( driverUrl: String, executorId: String, hostname: String, cores: Int, appId: String, workerUrl: Option[String], userClassPath: scala.Seq[URL]): Unit
When executed, run executes Utils.initDaemon(log).
CAUTION: FIXME What does initDaemon do?
NOTE: run spark-SparkHadoopUtil.md#runAsSparkUser[runs itself with a Hadoop UserGroupInformation] (as a thread local variable distributed to child threads for authenticating HDFS and YARN calls).
NOTE: run expects a clear hostname with no : included (for a port perhaps).
[[run-driverPropsFetcher]] run uses executor:Executor.md#spark_executor_port[spark.executor.port] Spark property (or 0 if not set) for the port to rpc:index.md#create[create a RpcEnv] called driverPropsFetcher (together with the input hostname and clientMode enabled).
run rpc:index.md#setupEndpointRefByURI[resolves RpcEndpointRef for the input driverUrl] and requests SparkAppConfig (by posting a blocking RetrieveSparkAppConfig).
IMPORTANT: This is the first moment when CoarseGrainedExecutorBackend initiates communication with the driver available at driverUrl through RpcEnv.
run uses SparkAppConfig to get the driver's sparkProperties and adds SparkConf.md#spark.app.id[spark.app.id] Spark property with the value of the input appId.
run rpc:index.md#shutdown[shuts driverPropsFetcher RPC Endpoint down].
run creates a SparkConf.md[SparkConf] using the Spark properties fetched from the driver, i.e. with the SparkConf.md#isExecutorStartupConf[executor-related Spark settings] if they SparkConf.md#setIfMissing[were missing] and the SparkConf.md#set[rest unconditionally].
If yarn/spark-yarn-settings.md#spark.yarn.credentials.file[spark.yarn.credentials.file] Spark property is defined in SparkConf, you should see the following INFO message in the logs:
INFO Will periodically update credentials from: [spark.yarn.credentials.file]
run spark-SparkHadoopUtil.md#startCredentialUpdater[requests the current SparkHadoopUtil to start start the credential updater].
NOTE: run uses spark-SparkHadoopUtil.md#get[SparkHadoopUtil.get] to access the current SparkHadoopUtil.
run core:SparkEnv.md#createExecutorEnv[creates SparkEnv for executors] (with the input executorId, hostname and cores, and isLocal disabled).
IMPORTANT: This is the moment when SparkEnv gets created with all the executor services.
run rpc:index.md#setupEndpoint[sets up an RPC endpoint] with the name Executor and <
(only in Spark Standalone) If the optional input workerUrl was defined, run sets up an RPC endpoint with the name WorkerWatcher and WorkerWatcher RPC endpoint.
[NOTE]¶
The optional input workerUrl is defined only when <
--worker-url is only used in spark-standalone-StandaloneSchedulerBackend.md[Spark Standalone].¶
run's main thread is blocked until rpc:index.md#awaitTermination[RpcEnv terminates] and only the RPC endpoints process RPC messages.
Once RpcEnv has terminated, run spark-SparkHadoopUtil.md#stopCredentialUpdater[stops the credential updater].
CAUTION: FIXME Think of the place for Utils.initDaemon, Utils.getProcessName et al.
run is used when CoarseGrainedExecutorBackend standalone application is <
== [[creating-instance]] Creating CoarseGrainedExecutorBackend Instance
CoarseGrainedExecutorBackend takes the following when created:
. [[rpcEnv]] rpc:index.md[RpcEnv] . driverUrl . [[executorId]] executorId . hostname . cores . userClassPath . core:SparkEnv.md[SparkEnv]
NOTE: driverUrl, executorId, hostname, cores and userClassPath correspond to CoarseGrainedExecutorBackend standalone application's <
CoarseGrainedExecutorBackend initializes the <
NOTE: CoarseGrainedExecutorBackend is created (to act as an RPC endpoint) when <
== [[onStart]] Registering with Driver -- onStart Method
[source, scala]¶
onStart(): Unit¶
NOTE: onStart is part of rpc:RpcEndpoint.md#onStart[RpcEndpoint contract] that is executed before a RPC endpoint starts accepting messages.
When executed, you should see the following INFO message in the logs:
INFO CoarseGrainedExecutorBackend: Connecting to driver: [driverUrl]
NOTE: <
onStart then rpc:index.md#asyncSetupEndpointRefByURI[takes the RpcEndpointRef of the driver asynchronously] and initializes the internal <onStart sends a blocking scheduler:CoarseGrainedSchedulerBackend.md#RegisterExecutor[RegisterExecutor] message immediately (with <
In case of failures, onStart <1 and the reason (and no notification to the driver):
Cannot register with driver: [driverUrl]
== [[RegisteredExecutor]] Creating Single Managed Executor -- RegisteredExecutor Message Handler
[source, scala]¶
RegisteredExecutor extends CoarseGrainedClusterMessage with RegisterExecutorResponse
When RegisteredExecutor is received, you should see the following INFO in the logs:
INFO CoarseGrainedExecutorBackend: Successfully registered with driver
CoarseGrainedExecutorBackend executor:Executor.md#creating-instance[creates a Executor] (with isLocal disabled) that becomes the single managed <
NOTE: CoarseGrainedExecutorBackend uses executorId, hostname, env, userClassPath to create the Executor that are specified when CoarseGrainedExecutorBackend <
If creating the Executor fails with a non-fatal exception, RegisteredExecutor <
Unable to create executor due to [message]
NOTE: RegisteredExecutor is sent when CoarseGrainedSchedulerBackend RPC Endpoint receives a RegisterExecutor (that is sent right before CoarseGrainedExecutorBackend RPC Endpoint <CoarseGrainedExecutorBackend <
== [[RegisterExecutorFailed]] RegisterExecutorFailed
[source, scala]¶
RegisterExecutorFailed(message)¶
When a RegisterExecutorFailed message arrives, the following ERROR is printed out to the logs:
ERROR CoarseGrainedExecutorBackend: Slave registration failed: [message]
CoarseGrainedExecutorBackend then exits with the exit code 1.
== [[KillTask]] Killing Tasks -- KillTask Message Handler
KillTask(taskId, _, interruptThread) message kills a task (calls Executor.killTask).
If an executor has not been initialized yet (FIXME: why?), the following ERROR message is printed out to the logs and CoarseGrainedExecutorBackend exits:
ERROR Received KillTask command but executor was null
== [[StopExecutor]] StopExecutor Handler
[source, scala]¶
case object StopExecutor extends CoarseGrainedClusterMessage
When StopExecutor is received, the handler turns <
INFO CoarseGrainedExecutorBackend: Driver commanded a shutdown
In the end, the handler sends a <
StopExecutor message is sent when CoarseGrainedSchedulerBackend RPC Endpoint (aka DriverEndpoint) processes StopExecutors or RemoveExecutor messages.
== [[Shutdown]] Shutdown Handler
[source, scala]¶
case object Shutdown extends CoarseGrainedClusterMessage
Shutdown turns <CoarseGrainedExecutorBackend-stop-executor thread that executor:Executor.md#stop[stops the owned Executor] (using <
NOTE: Shutdown message is sent exclusively when <
== [[exitExecutor]] Terminating CoarseGrainedExecutorBackend (and Notifying Driver with RemoveExecutor) -- exitExecutor Method
[source, scala]¶
exitExecutor( code: Int, reason: String, throwable: Throwable = null, notifyDriver: Boolean = true): Unit
When exitExecutor is executed, you should see the following ERROR message in the logs (followed by throwable if available):
Executor self-exiting due to : [reason]
If notifyDriver is enabled (it is by default) exitExecutor informs the <RemoveExecutor message with <ExecutorLossReason with the input reason).
You may see the following WARN message in the logs when the notification fails.
Unable to notify the driver due to [message]
In the end, exitExecutor terminates the CoarseGrainedExecutorBackend JVM process with the status code.
NOTE: exitExecutor uses Java's https://docs.oracle.com/javase/8/docs/api/java/lang/System.html#exit-int-[System.exit] and initiates JVM's shutdown sequence (and executing all registered shutdown hooks).
[NOTE]¶
exitExecutor is used when:
-
CoarseGrainedExecutorBackend fails to <
-
no <
* <>.¶
== [[onDisconnected]] onDisconnected Callback
CAUTION: FIXME
== [[start]] start Method
CAUTION: FIXME
== [[stop]] stop Method
CAUTION: FIXME
== [[requestTotalExecutors]] requestTotalExecutors
CAUTION: FIXME
== [[extractLogUrls]] Extracting Log URLs -- extractLogUrls Method
CAUTION: FIXME
== [[logging]] Logging
Enable ALL logging level for org.apache.spark.executor.CoarseGrainedExecutorBackend logger to see what happens inside.
Add the following line to conf/log4j.properties:
[source,plaintext]¶
log4j.logger.org.apache.spark.executor.CoarseGrainedExecutorBackend=ALL¶
Refer to spark-logging.md[Logging].
== [[internal-properties]] Internal Properties
=== [[ser]] SerializerInstance
serializer:SerializerInstance.md[SerializerInstance]
Initialized when <
NOTE: CoarseGrainedExecutorBackend uses the input env to core:SparkEnv.md#closureSerializer[access closureSerializer].
=== [[driver]] Driver RpcEndpointRef
rpc:RpcEndpointRef.md[RpcEndpointRef] of the driver
=== [[stopping]] stopping Flag
Enabled when CoarseGrainedExecutorBackend gets notified to <
Default: false
Used when CoarseGrainedExecutorBackend RPC Endpoint gets notified that <
=== [[executor]] Executor
Single managed coarse-grained executor:Executor.md#coarse-grained-executor[Executor] managed exclusively by the CoarseGrainedExecutorBackend to forward <
Initialized after CoarseGrainedExecutorBackend <