Apache Spark¶
Apache Spark 是一个 开源的分布式通用集群计算框架 具备大多数 内存数据处理引擎 的能力,可以在静态(批处理)或动态(流处理)的大规模数据上进行ETL、分析、机器学习和图计算,具有丰富简洁的高级API,同时支持Scala, Python, Java, R, 和SQL多个编程语言版本.
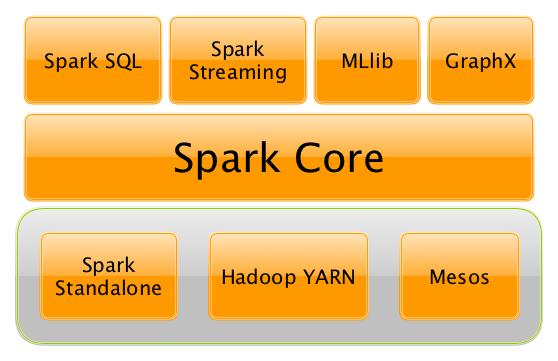
你也可以把Spark描述为一个分布式的数据处理引擎,用于*批处理和流模式*,具有SQL查询、图形处理和机器学习的功能。
与Hadoop基于磁盘的两阶段MapReduce计算引擎相比,Spark的多阶段(大部分)内存计算引擎允许在内存中运行大多数计算,因此在大多数时候为某些应用提供更好的性能,例如迭代算法或交互式数据挖掘。(阅读 Spark officially sets a new record in large-scale sorting).
Spark的目标是速度、易用性、可扩展性和互动分析。
Spark是一个**分布式平台,用于执行复杂的多阶段应用**,如**机器学习算法**,以及**交互式实时查询(ad hoc queries)**。Spark为内存集群计算提供了一个高效、抽象的编程接口,称为 Resilient Distributed Dataset.
使用Spark应用框架,可以简化在大数据规模下进行机器学习和预测性分析的门槛。
Spark 内部是通过 Scala (JVM 系语言)编写, 但也为Java、Python和R等其他语言开发者提供了API.
如果你有大量的数据,典型的MapReduce程序无法提供的低延迟处理要求,那么Spark是一个可行的选择。
- 跨越任何数据源访问任何数据类型。
- 对存储和数据处理有巨大的需求。
Apache Spark 项目包含spark-sql (with Datasets), streaming, machine learning (pipelines) 以及 graph 图计算引擎 等模块 建立在 Spark Core核心模块之上. 你可以在单一的应用程序中使用统一的API运行它们。
Spark既可以在本地运行,也可以在集群中运行,在企业内部或在云中运行。它在Hadoop YARN、Apache Mesos的基础上运行,独立运行或在云中运行(亚马逊EC2或IBM Bluemix)。
Apache Spark的 Structured Streaming and SQL编程模型和 MLlib 以及 GraphX 使开发者和数据科学家更容易建立利用机器学习和图分析的应用程序.
在顶层设计上,任何Spark应用程序都会从一些输入中创建RDDs,运行(lazy) transformations得到一些其他形式(形状)的RDDs,最后执行actions来收集或储存数据。简单的设计原则,是吧?
你可以从程序员、数据工程师和管理员的角度来看待Spark。说实话,这三类人都会在Spark上花费相当多的时间,最终达到利用所有可用功能的地步。程序员使用特定语言的API(并使用转换和动作在RDD的水平上工作),数据工程师使用更高层次的抽象,如DataFrames或Pipelines API或外部工具(连接到Spark),最后这一切只能因为管理员设置了Spark集群来部署Spark应用而得以运行。
Spark的目标是成为一个通用的计算平台,在一个统一的引擎之上有各种专门的应用框架。
注意:当你听到 "Apache Spark "时,它可以是两件事--Spark引擎,又称*Spark Core*或Apache Spark开源项目,它是Spark Core和伴随的Spark应用框架的一个 "总称",即 Spark SQL、spark-streaming/Spark Streaming、Spark MLlib和Spark GraphX,它们位于Spark Core之上,Spark的主要数据抽象称为RDD - Resilient Distributed Dataet。
为什么要选用Spark¶
让我们首先列举一下Spark流行的众多原因中的几个,然后是借以提供更多技术帮助的概述。
快速上手¶
Spark提供了spark-shell,这使得在你的笔记本电脑上用命令行编写和运行Spark应用程序变得非常容易上手。
然后你可以使用Spark Standalone内置的集群管理器,将你的Spark应用部署到生产级集群中,在完整的数据集上运行。
适用于不同工作场景的统一计算引擎¶
正如Matei Zaharia —— Apache Spark的作者在 Introduction to AmpLab Spark Internals video所言:
One of the Spark project goals was to deliver a platform that supports a very wide array of diverse workflows - not only MapReduce batch jobs (there were available in Hadoop already at that time), but also iterative computations like graph algorithms or Machine Learning.
And also different scales of workloads from sub-second interactive jobs to jobs that run for many hours.
Spark将批处理、交互式和流式工作统一在一个丰富简洁的API下。
Spark通过Spark Streaming应用框架支持*近乎实时的流式工作负载*。
ETL工作负载和分析工作负载是不同的,然而Spark试图为各种工作负载提供一个统一的平台。
图形和机器学习算法在本质上是迭代的,更少地保存到磁盘或通过网络传输意味着更好的性能。
此外,还支持使用Spark shell的交互式工作负载。
你应该观看Cloudera公司首席战略官兼联合创始人Mike Olson的视频什么是Apache Spark?,他对Apache Spark、其在开源社区的流行程度以及Spark如何准备取代MapReduce作为Hadoop的一般处理引擎进行了非常出色的概述。
充分利用分布式批处理数据的最佳方法¶
当你想到*分布式的批量数据处理*时,自然而然地想到了Hadoop这么一个可行的解决方案。
Spark从Hadoop MapReduce中汲取了许多想法。它们在一起工作得很好--YARN和HDFS上的Spark--同时改进了分布式计算引擎的性能和简单性。
对许多人来说,Spark是Hadoop++,即以更好的方式完成MapReduce。 利用分布式批处理数据的最佳方式
这也*不*应该是惊喜,如果没有Hadoop MapReduce(它的进步和不足),Spark根本不会诞生。
RDD - 分布式并行Scala集合¶
作为一个Scala开发者,你可能会发现Spark的RDD API非常相似于Scala's Collections API.
它也被暴露在Java、Python和R中(以及SQL,即SparkSQL,在某种意义上)。
因此,当你需要Scala中的分布式集合API时,带有RDD API的Spark应该是一个重要的竞争者。
丰富的标准库¶
你不仅可以在Spark中使用map和reduce(如Hadoop MapReduce作业),还可以使用大量其他更高级别的运算符,以方便你的Spark查询和应用开发。
它扩展了可用的计算方式,超越了Hadoop MapReduce中唯一可用的map和reduce。
统一的开发和部署环境¶
无论你使用何种Spark工具--支持多种编程语言的Spark API--Scala、Java、Python、R或Spark shell,或利用RDD概念的许多Spark应用框架,即Spark SQL、Spark Streaming、 Spark MLlib和Spark GraphX,你仍然使用相同的开发和部署环境来处理大型数据集以产生结果,无论是预测(Spark MLlib)、结构化数据查询(Spark SQL)或只是大型分布式批量(Spark Core)或流(Spark Streaming)计算。
团队可以利用团队成员目前所掌握的不同技能,这也是Spark非常有成效的地方。数据分析师、数据科学家、Python程序员、或Java、或Scala、或R,都可以使用同一个Spark平台,使用量身定做的API。这使得将具有不同编程语言专长的熟练人员聚集到一个Spark项目中。
交互式探索/探索式分析¶
它也被称为ad hoc查询(临时查询)。
使用Spark shell你可以执行计算来处理大量的数据(大数据)。这都是交互式的,对于在最终生产发布之前探索数据非常有用。
另外,使用Spark shell你可以访问任何Spark集群,就像访问你的本地机器一样。只需将Spark shell指向一个总内存为10TB的20个节点(使用--master),并使用所有的组件(及其抽象),如Spark SQL、Spark MLlib、Spark Streaming,以及Spark GraphX。
根据你的需求和技能,你可能会看到更适合SQL与编程API或从图数据结构(Spark GraphX)中的数据应用机器学习算法(Spark MLlib)。 另外,使用Spark shell你可以访问任何spark-cluster.md[Spark集群],就像访问你的本地机器一样。只需将Spark shell指向一个总内存为10TB的20个节点(使用--master),并使用所有的组件(及其抽象),如Spark SQL、Spark MLlib、spark-streaming/spark-streaming.md[Spark Streaming],以及Spark GraphX。
简单的环境¶
无论你擅长哪种编程语言,无论是Scala、Java、Python、R还是SQL,你都可以使用相同的单一集群运行环境进行原型设计、临时查询,并利用Spark平台提供的许多摄取数据点部署你的应用程序。
你可以像直接使用底层的RDD API,或者利用Spark SQL(数据集)、Spark MLlib(ML管道)、Spark GraphX(图)或Spark Streaming(DStreams)的高级API。
或者在一个单一的应用程序中使用它们。
用于不同种类工作负载的单一编程模型和执行引擎简化了开发和部署架构。
丰富数据源的数据集成工具包¶
Spark可以从许多类型的数据源中读取数据--关系型、NoSQL、文件系统等。支持许多类型的数据格式--Parquet, Avro, CSV, JSON。
程序员和数据工程师使用Spark作为平台,对大量的数据进行交互(使用Spark shell)或在应用程序中读取或保存到处理,即支持输入和输出这两种数据源。
开箱即用的工具¶
正如为工作挑选合适的工具建议一样,这并不总是可行的。时间、个人偏好、你工作的操作系统都是决定什么是正确的因素(使用锤子也可以是一个合理的选择)。
Spark在一个统一的开发和运行环境中囊括了许多概念。
- 在Python中功能非常丰富的机器学习工具,例如SciKit库,现在可以被Scala开发者使用(作为Spark MLlib中的Pipeline API或调用
pipe())。 - 来自R的DataFrames可以在Scala、Java、Python、R API中使用。
- 机器学习算法中的单节点计算被迁移到Spark MLlib中的分布式版本。
这个单一的平台给Python、Scala、Java和R程序员以及数据工程师(SparkR)和科学家(使用Thrift JDBC/ODBC Server的专有企业数据仓库)提供了大量的机会。
请注意这句谚语如果你只有一把锤子,一切看起来都像钉子,也是如此。
底层优化¶
Apache Spark使用一个调度器:计算阶段的有向无环图(DAG)(又称*执行DAG*)。它将任何处理推迟到真正需要的行动。Spark的*lazy evaluation*提供了大量的机会来执行底层的优化(所以用户必须知道的更少,做的更多)。
谚语less is more.
在低延迟的迭代工作负载方面表现出色¶
Spark支持不同的工作负载,由于针对低延迟的迭代工作的出色表现。它们经常被用于机器学习和图形算法中。
许多机器学习算法需要大量的迭代,才能得到最佳的结果模型,比如逻辑回归。这同样适用于图算法,在需要时遍历所有的节点和边。当临时的部分结果被存储在内存或非常快的固态硬盘上时,这样的计算可以提高其性能。
Spark可以将中间数据缓存在内存中以加快模型的建立和训练。一旦数据被加载到内存中(作为初始步骤),多次重复使用不会产生性能减弱。
另外,图算法可以在每次迭代中遍历图的一个连接,部分结果在内存中。
当你需要处理大量的数据时,特别是当它是一个大数据时,更少的磁盘访问和网络可以产生巨大的差异。
更容易完成ETL¶
Spark开启了 ETL 新时代,支持众多编程语言--Scala、Java、Python(不太可能是R)。你全都可以使用它们,也可以为特定问题挑选最好的。
特别是与其他语言和方法如Java中的MapReduce相比,Scala在Spark中的应用,使得模板代码大大减少。
统一简明的高级别API¶
Spark为批处理分析(RDD API)、SQL查询(Dataset API)、实时分析(DStream API)、机器学习(ML Pipeline API)和图形处理(Graph API)提供了*统一的、简洁的、高级的API。
开发人员不再需要学习许多不同的处理引擎和平台,而让时间花在掌握每个用例的框架API上(在单一计算引擎Spark之上)。
使用统一的API进行不同种类的数据处理¶
Spark利用统一的API和数据结构提供了三种数据处理方式,即*批处理*、*交互式处理*和*流处理。
更少的磁盘IO,更强的性能¶
在不长的时间里,当最普遍的分布式计算框架是Hadoop MapReduce时,只有在你把它写入外部存储,如Hadoop Distributed Filesystem(HDFS)之后,你才可以在计算之间重复使用一个数据(甚至是部分数据!)。即使是非常基本的多阶段计算,它也会花费你大量的时间。它只是遭受了IO(也许还有网络)的开销。
构建Spark的众多动机之一就是要有一个善于数据重用的框架。
Spark以一种方式将尽可能多的数据保留在内存中,并将其保留到作业完成。多少个阶段属于一个作业并不重要。重要的是可用的内存和你使用Spark API的效率(参考[没有shuffle发生](rdd\index.md))。
网络和磁盘IO越少,性能就越好,Spark努力寻找方法来减少这两方面。
容错性¶
故障在Spark中不被认为是一种特殊情况,而是作为一个并行和分布式系统的明显结果。Spark在默认情况下处理和恢复故障,不需要特别复杂的逻辑来处理它们。 构建Spark的众多动机之一就是要有一个善于数据重用的框架。 Spark以一种方式将尽可能多的数据保留在内存中,并将其保留到作业完成。多少个阶段属于一个作业并不重要。重要的是可用的内存和你使用Spark API的效率(所以rdd:index.md[没有shuffle发生])。
社区开源¶
Spark的设计相当简单,与它提供的功能相比,它的代码并不庞大。
Spark合理的小代码库邀请了项目贡献者--以更稳定的速度扩展平台和修复错误的程序员。
了解更多¶
进一步阅读或观看
Keynote: Spark 2.0 - Matei Zaharia, Apache Spark Creator and CTO of Databricks