Concurrency Model and Event Loop
refer from jscomplete.com, author Samer Buna
Introduction
One of the most important concepts to understand about Node. js is its concurrency model for handling multiple connections and the use of callbacks. You might know this as the non-blocking nature of Node. js. In Node, this model is based on an event model, just like Ruby’s ‘Event Machine’, or Python’s ‘Twisted’. In Node, this event model is organized through what’s known as the event loop. Slow I/O operations are handled with events and callbacks so that they don’t block the main single-threaded execution runtime. Everything in Node depends on this concept so it’s extremely important that you fully understand it.
What Is I/O Anyway
Okay, so we know that I/O is short for input/output, but what exactly does that mean? I/O is used to label a communication between a process in a computer CPU and anything external to that CPU, including memory, disk, network, and even another process. The process communicates with these external things with signals or messages. Those signals are input when they are received by the process, and output when they are sent out by the process. The term I/O is really overused, because naturally, almost every operation that happens inside and outside computers is an I/O operation, but when talking about Node’s architecture, the term I/O is usually used to reference accessing disk and network resources, which is the most time-expensive part of all operations. Node’s event loop is designed around the major fact that the largest waste in computer programming comes from waiting on such I/O operations to complete. We can handle requests for these slow operations in one of many ways. We can just execute things synchronously. This is the easiest way to go about it, but it’s horrible because one request is going to hold up other requests. We can fork a new process from the OS to handle each request, but that’s probably won’t scale very well with a lot of requests. The most popular method for handling these requests is threads. We can start a new thread to handle each request. But threaded programming can get very complicated when threads start accessing shared resources. A lot of popular libraries and frameworks use threads. For example, Apache is multithreaded and it usually creates a thread per request. On the other hand, its major alternative, Nginx is single threaded, just like Node, which eliminates the overhead created by these multiple threads and simplify coding for shared resources. Single threaded frameworks like Node use an event loop to handle requests for slow I/O operations without blocking the main execution runtime. This is the most important concept to understand about Node, so how exactly does this event loop work? Let’s find out.
The Event Loop
The simplest one-line definition of the event loop is this.
It’s the entity that handles external events and converts them into callback invocations.
Maybe not. Let’s try another definition:
It’s the loop that picks events from the event queue and pushes their callbacks to the call stack.
This definition is probably worse than the first one. Truth is, it’s not easy to understand the event loop without first understanding the data structures it has to deal with. It’s also a lot easier to understand the event loop with visuals rather than text, so lets in some samples. What we need to understand first is that there is this thing called the event loop that Node automatically starts when it executes a script, so there is no need for us to manually start it.his event loop is what makes the asynchronous callback programming style possible. Node will exit the event loop when there are no more callbacks to perform. The event loop is also present in browsers and it’s very similar to the one that fires in Node. To understand event loop, we need to understand all the players in this diagram and we need to understand how they interact.
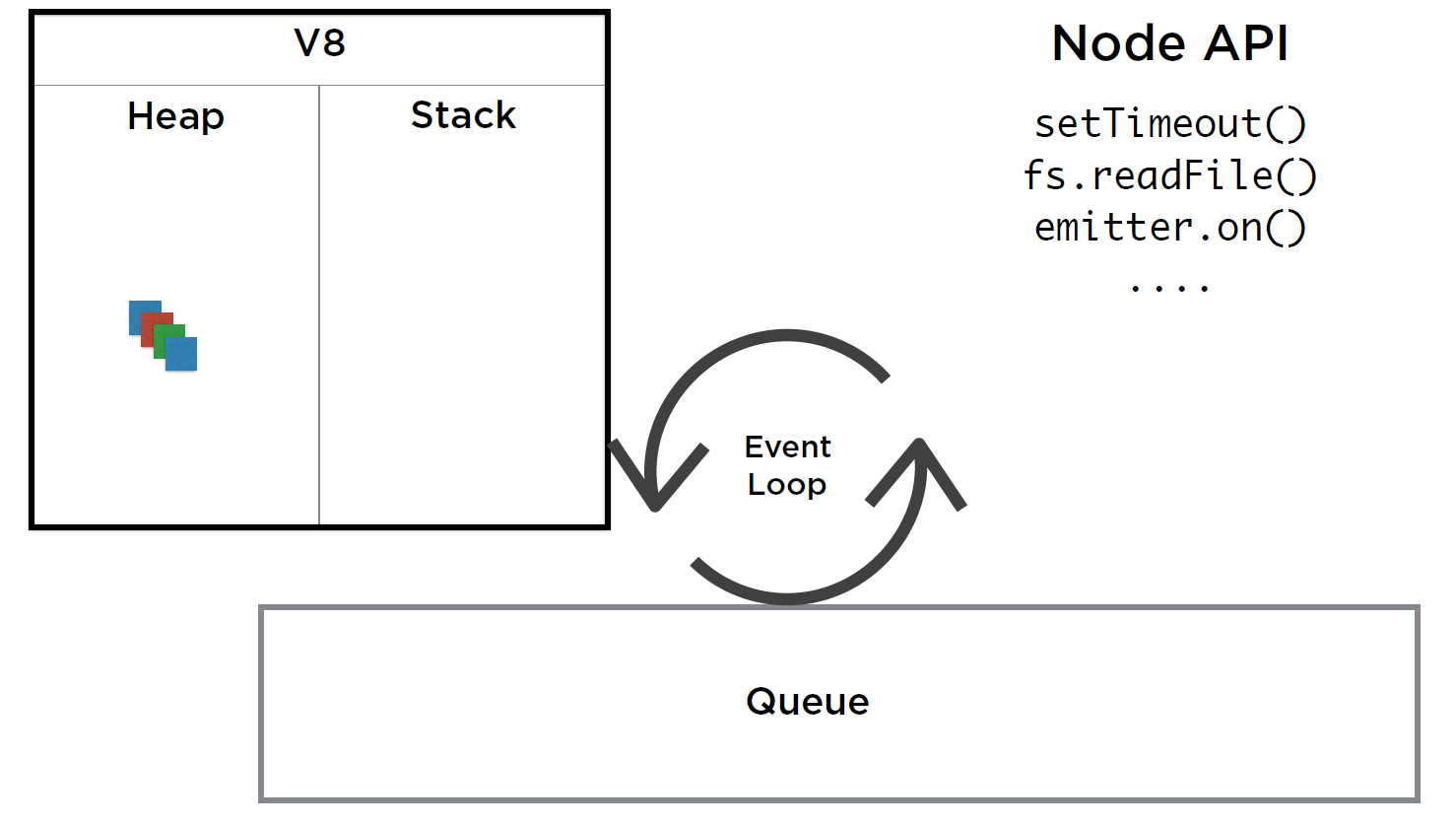
So V8 has this thing called stack, will cover in detail in the next section. It also has a heap. The heap is simple, it is where objects are stored in memory. It’s basically the memory that gets allocated by the VM for various tasks. For example, when we invoke a function, an area in this heap is allocated to act as the local scope of that function. Both the Stack and the Heap are part of the run-time engine, not Node itself. Node adds APIs like ``timers, emitters, and wrappers around OS operations. It also provides the event Queue and the event loop using the libuv library. The event loop, as the name clearly describe, is a simple loop that works between the event queue and the call stack.
The Call Stack
The V8 Call stack which is simply a list of functions. A stack is a first in last out simple data structure. The top element that we can pop out of the stack is the last element that we pushed into it. In the case of V8 Call stack, these elements are functions. Since JavaScript is single threaded, there is only one stack, and it can do one thing at a time. If the stack is executing something, nothing else will happen in that single thread. When we call multiple functions that call each other, we naturally form a stack. Then we back-track the function invocations all the way back to the first caller. Remember how if you want to implement something that’s recursive without recursion you need to use a stack? Well, that’s because a normal recursive function will use a stack anyway. Let’s walk through a simple example to demonstrate what happens in the stack when we call functions. Here we have three simple functions, add, double (which calls add), and printDouble which calls double, and let’s assume that all these functions are wrapped in an immediately invoked function expression. When we run this code, V8 uses the stack to record where in the program it is currently executing. Every time we step into a function, it gets pushed to the stack, and every time we return from a function, it gets popped out of the stack. It’s really that simple. So we start with the IIFE call, which is an anonymous function. Push that to the stack. The IIFE function defines other functions, but only executes printDouble. That gets pushed to the stack. PrintDouble calls double, so we push double to the stack, double calls add, we push add to the stack, and so far, we’re still executing all functions. We have not returned from any of them. When we return from add, we pop add out of the stack. We’re done with it. Then we return from double, so double gets popped out of the stack, too. Now, the execution continues in printDouble. We get into a new function call, console. log, that get’s pushed into the stack and popped immediately, because it did not call any other functions. Then we implicitly return from printDouble, so we pop printDouble out of the stack and finally pop the anonymous IIFE itself out of the stack. Note how every time a function is added to the stack, its arguments and local variables are added too in that same level. You’ll sometimes hear the term stack frame to reference the function and its arguments and local variables. I am pretty sure you have seen the call stack before, if not in node then the browser. Every time you get an error, the console will show the call stack. And what do you think will happen if a function calls itself recursively without an exit condition? It’s the equivalent of an infinite loop, but on the stack. We’ll keep pushing the same function to the stack until we reach the V8 size limit for the stack, and V8 will error out with this error: Maximum call stack size exceeded.

Handling Slow Operations
As long as the operations we execute in the call stack are fast, there is no problem with having a single thread, but when we start dealing will slow operations, the fact that we have a single thread becomes a problem, because these slow operations will block the execution. Let me simulate that for you with an example. You do know that we can still write blocking code in Node, right? For example, a long for loop is a blocking operation. In here the slowAdd function will take a few seconds to complete, depending on the hardware, of course. So what happens in the call stack when we step into a blocking function like slowAdd? Well, the first time we step into it, it gets pushed to the stack, and then we wait until V8 finishes that useless blocking loop and returns from slowAdd(3, 3) which gets popped out of the stack at that point. Then we step into slowAdd 4 4, and we wait, done, return, pop. Same thing for slowAdd 5 5, wait, done, return, pop. Then we get into the console. log lines, which are fast and thus non blocking, so push, pop, push, pop, push, and pop. Let me actually show you how Node behaves when we execute this exact code, slowAdd, wait, slowAdd, wait, slowAdd, wait, print, print, print. While Node is waiting after every slowAdd here, it cannot do anything else. This is blocking programming, and Node’s event loop exists to allow us to avoid doing this style of programming.
const slowAdd = (a,b)=>{
for(let i = 0; i< 100000; i++){
}
return a + b;
}
// slow
const a = slowAdd(1,2)
const b = slowAdd(3,4)
const c = slowAdd(5,6)
const d = slowAdd(7,8)
// quick
console.log(a)
console.log(b)
console.log(c)
console.log(d)
How Callbacks Actually Work
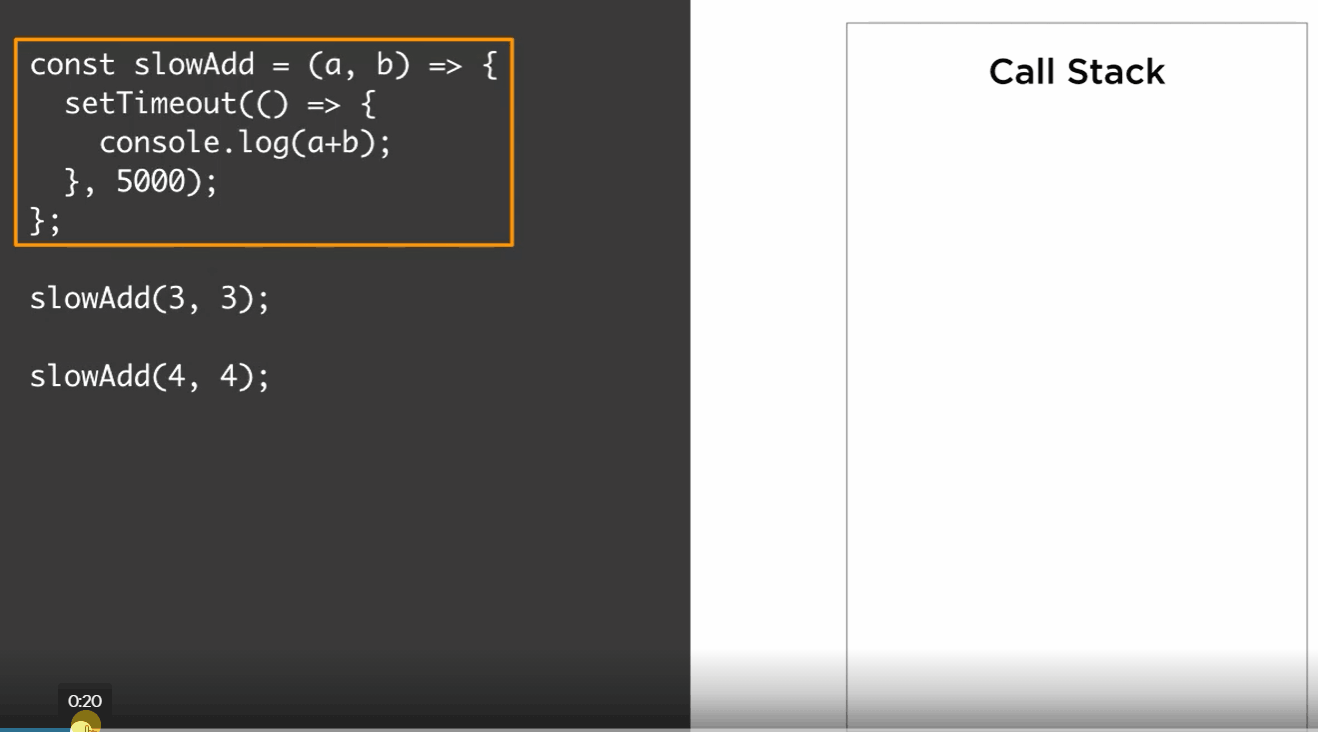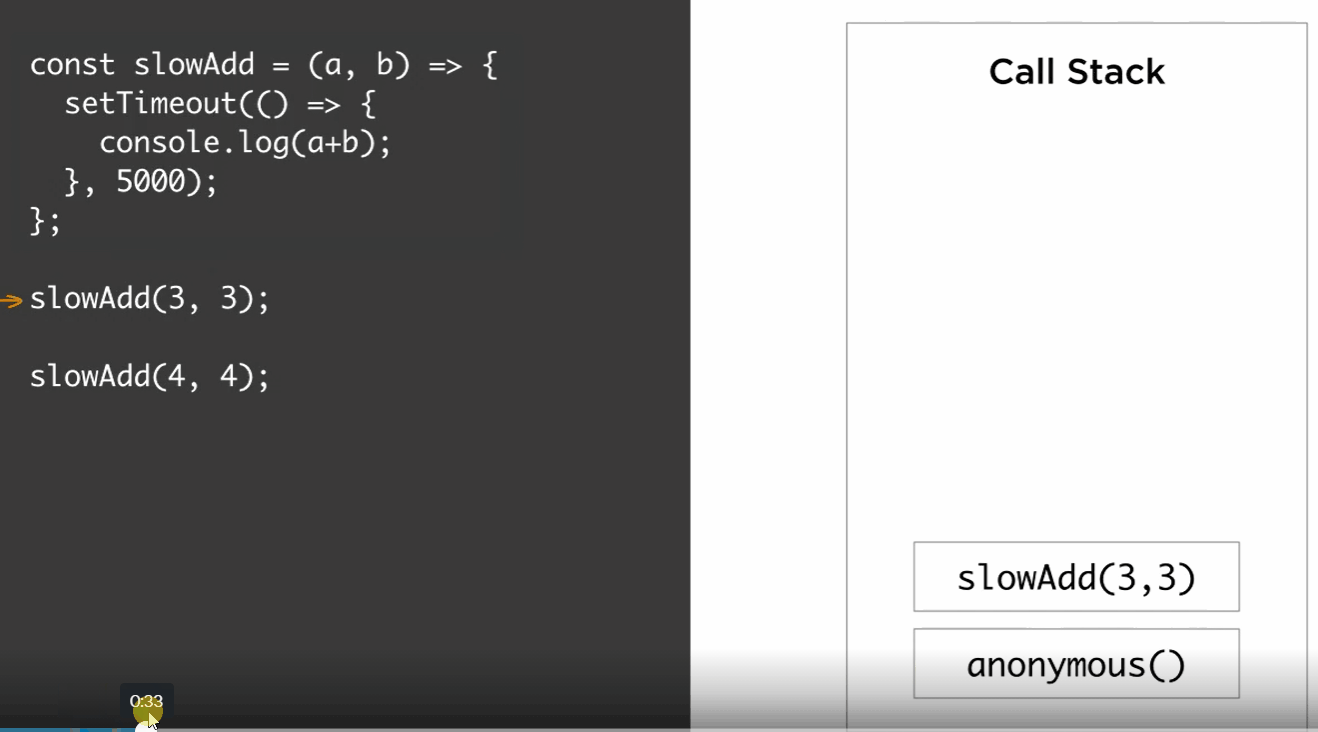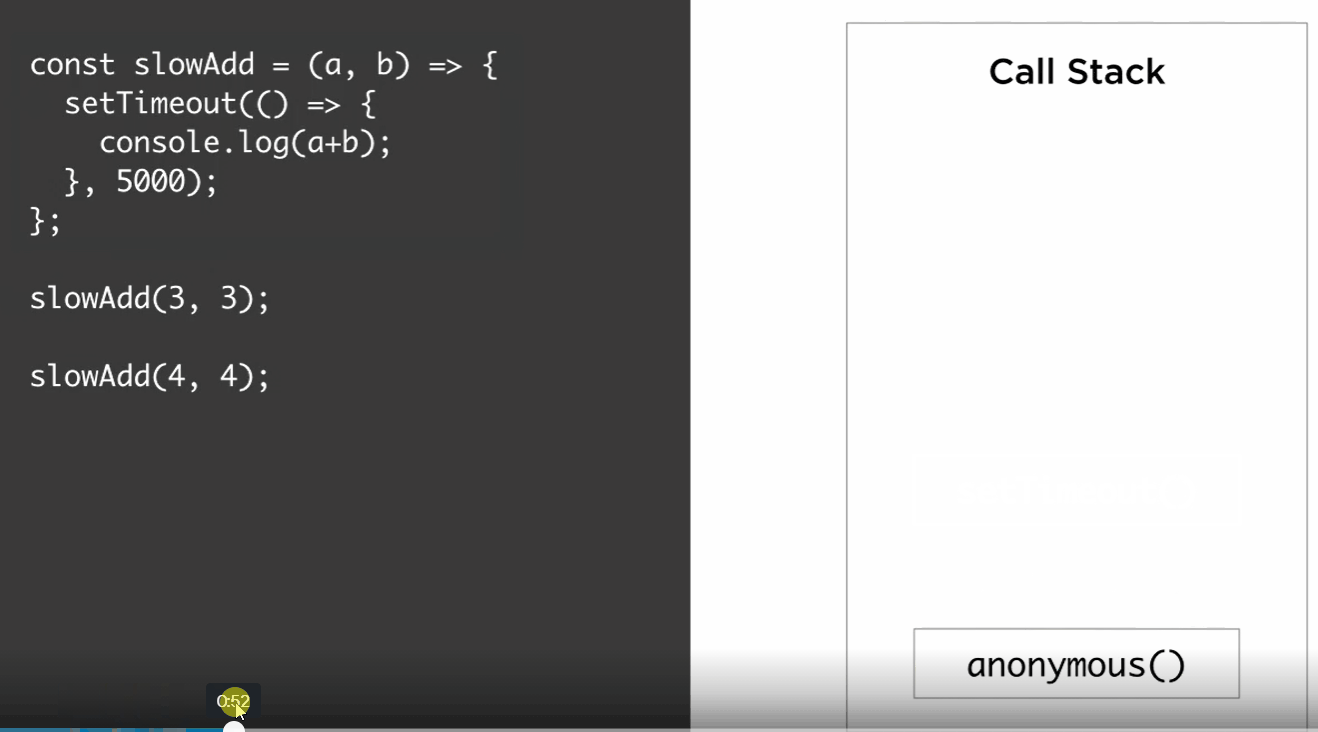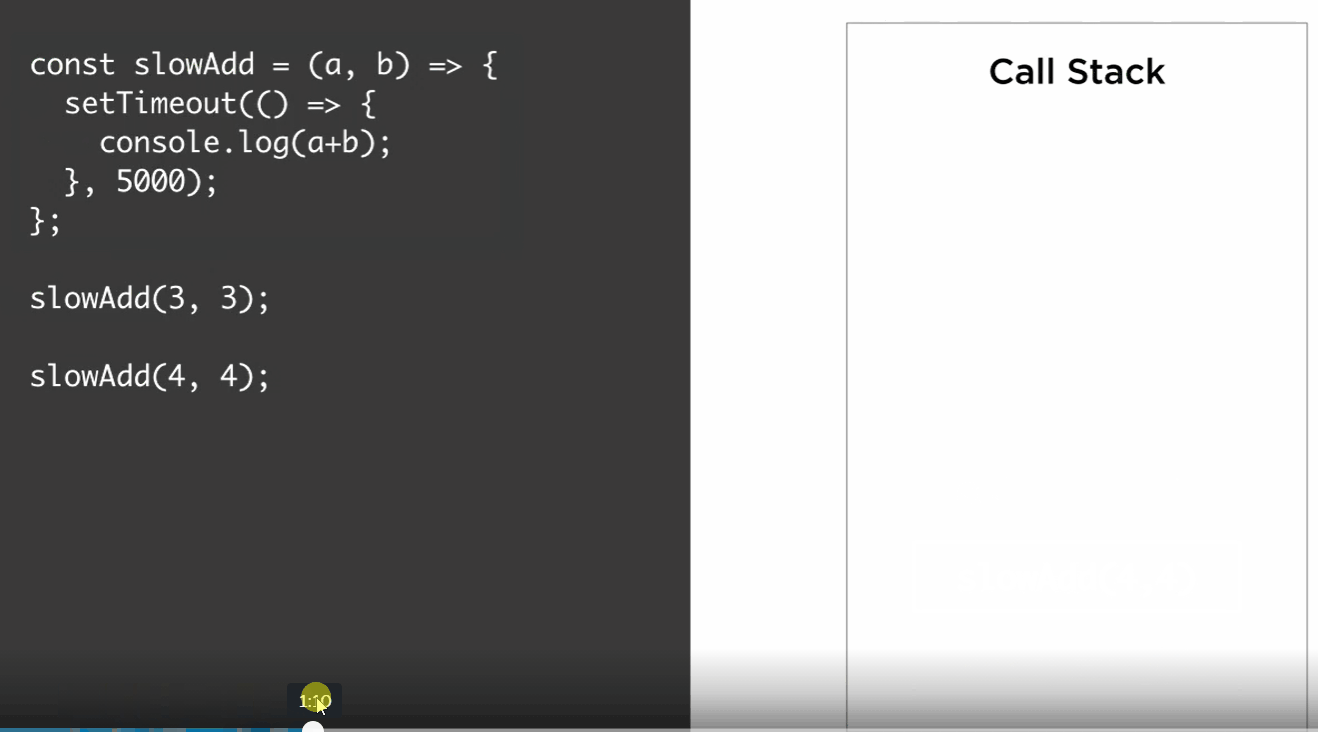
We all know that Node API is designed around callbacks. We pass functions to other functions as arguments, and those argument functions get executed at a later time, somehow. For example, if we change our slowAdd function to output the result in a setTimeout call after five seconds, the first argument to setTimeout is the function that is famously known as a callback. So let’s see what happens on the stack for this case.
const slowAdd = (a,b)=>{
setTimeout(()=>{
for(let i = 0; i< 100000; i++) {}
return a + b;
},5000)
}
slowAdd(3,3)
slowAdd(4,4)
We call slowAdd(3,3), push that to the stack, slowAdd calls setTimeout, so we push that to the stack, since setTimeout does not call any functions but rather has a function argument, it gets popped out of stack immediately, and at that point, slowAdd(3,3) is done, so we pop that out of the stack too. Then we continue, slowAdd(4,4), push it to stack, calls setTimeout, push that to the stack and immediately pop it, then pop slowAdd(4,4), then somehow, console.log(6) gets added to the stack to be executed, and after that, console.log(8) gets added to the stack to be executed.
To understand how the last two calls to console. log appeared in the call stack, let’s take a look at the bigger picture here. First, it’s important to understand that an API call like setTimeout is not part of **V8. It’s provided by Node itself, just like it’s provided by browsers**, too. It’s wired in a way to work with the event loop asynchronously. That’s why it behaves a bit weirdly on the normal call stack.
Let’s talk about the event queue, which is sometimes called the message queue or the callback queue. It’s simply a list of things to be processed; let’s call these things events. When we store an event on the queue, we sometimes store a plain-old function with it. This function is what we know as a callback. A queue data structure is a first in first out structure, so the first event we queue will be the first event to get de-queued. To de-queue and process an event from the edge of the queue, we just invoke the function associated with it. Invoking a function will push it to the stack.
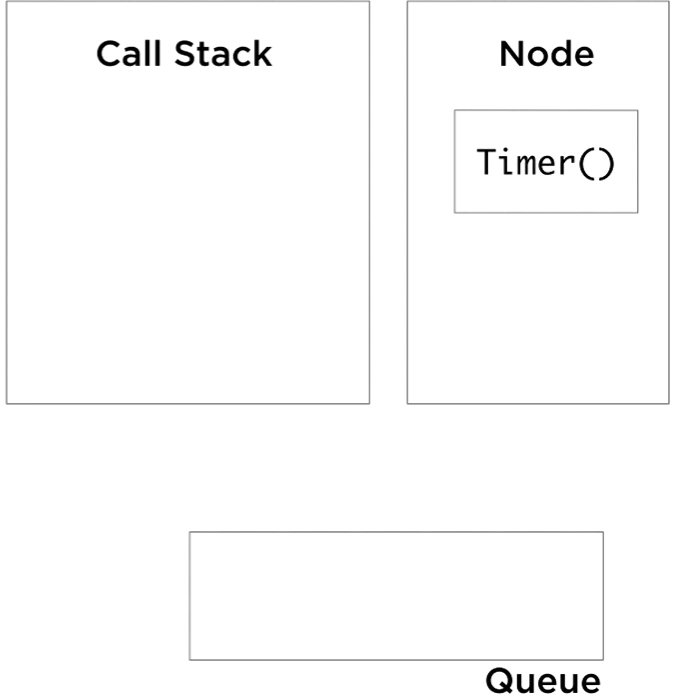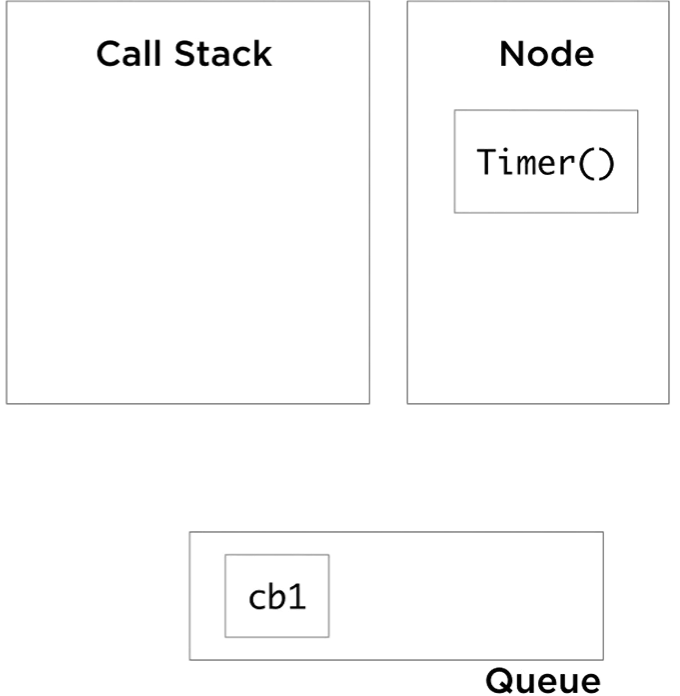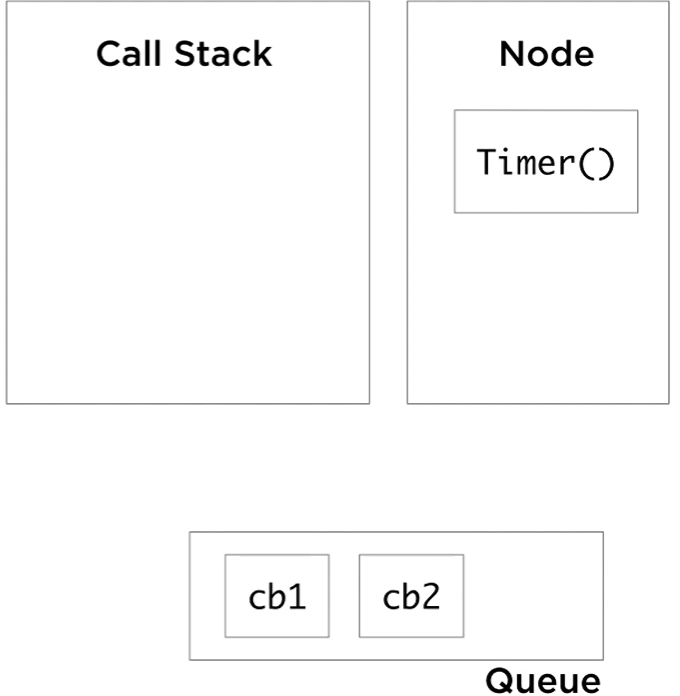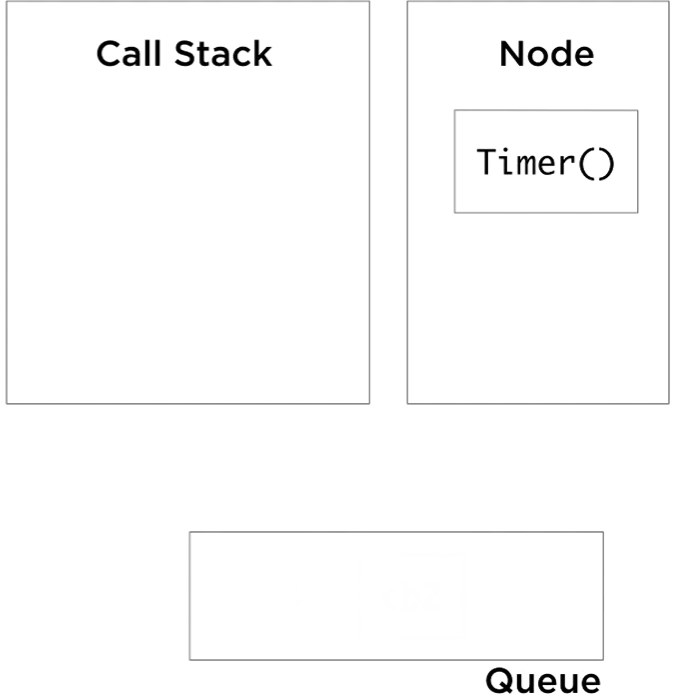
So we start with the anonymous function, it pushes slowAdd(3,3) to the call stack, which in turn pushes setTimeout cb 1, delay of 5 seconds. The setTimeout callbacks here in this example are actually anonymous functions, but to simplify the visualization, I labeled them cb1 and cb2. At this point, Node sees a call to its setTimeout API, takes note of it, and instantiate a timer outside of the JavaScript runtime. The setTimeout call on the stack will be done and popped out, and while the Node timer is running, the stack is free to continue processing its items. It pops slowAdd(3,3), pushes slowAdd(4,4), which in turn pushes setTimeout with the second callback. Node kick off another timer for this new setTimeout call and the stack continues to pop its done functions. After five seconds, both timers complete, and when they do they queue the callbacks associated with them into the event queue.

Exactly at this moment, the event loop has something important to do. The event loop job is super simple. It monitors the call stack and the event queue. When the stack is empty, and the queue is not empty (there are events waiting to be processed in the queue), it will de-queue one event from the queue and push its callback to the stack. It’s called an event loop, because it loops this simple logic until the event Queue is empty.
Right now, our example’s call stack is empty and the queue is not. The event loop will pick cb1, and push it to the stack. Cb1 will push console. log call to the stack, which returns immediately, and this marks cb1 as done. The stack is empty again, and we still have one event to process, so the event loop will push cb2 to the stack and cb2 pushes console. log, done, pop, cb2 is done, and we are at an idle state now for the event loop. The stack is empty and the queue is empty. Node will exit the process when we reach this state.
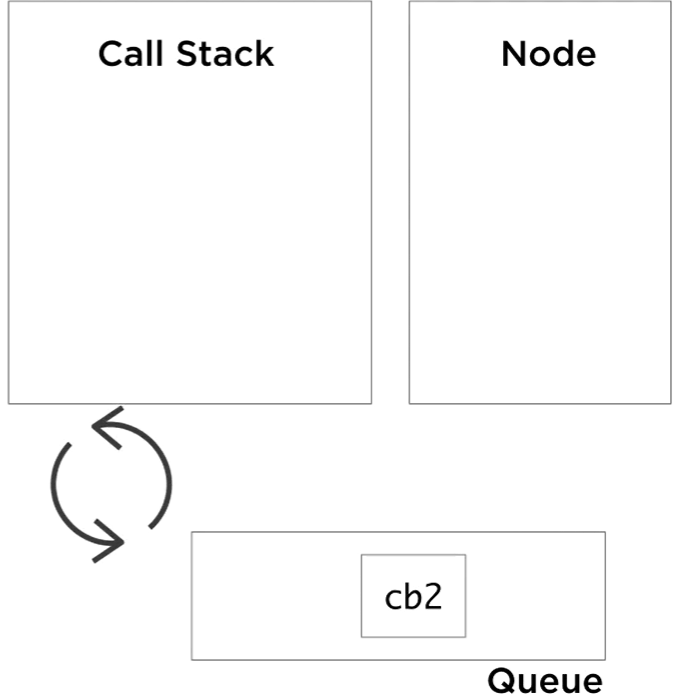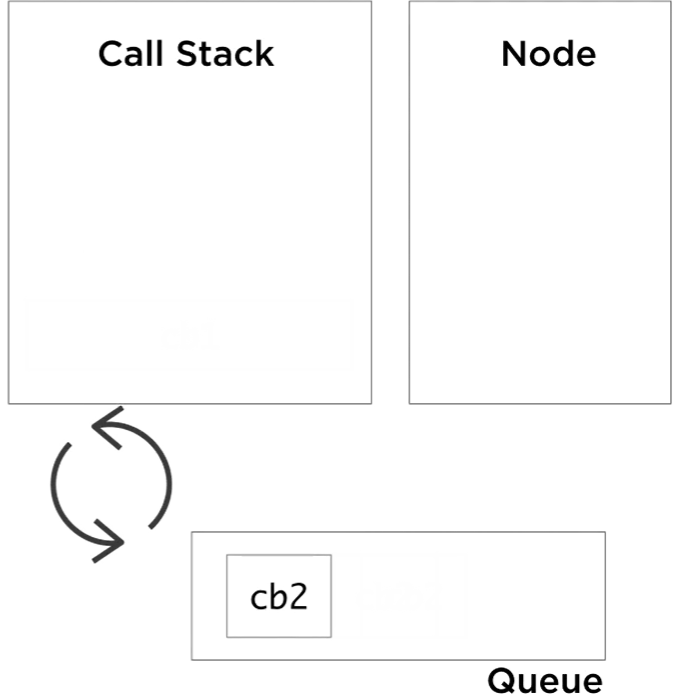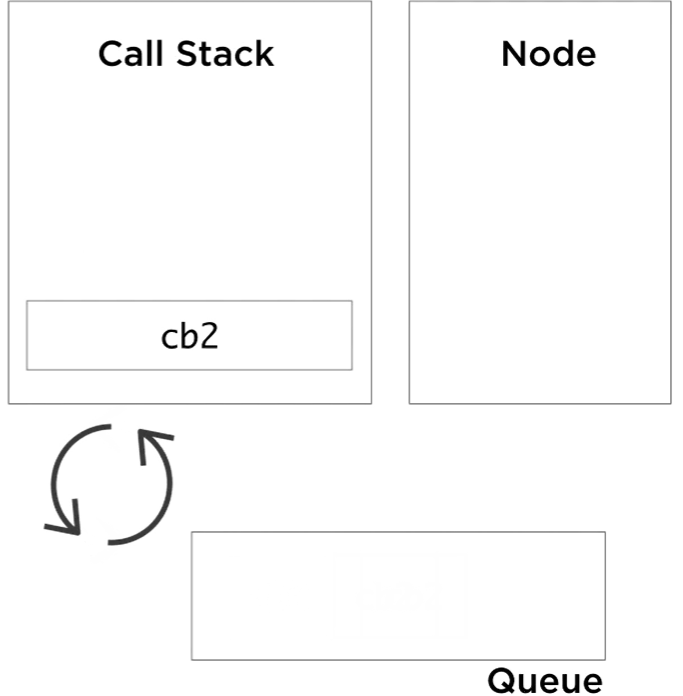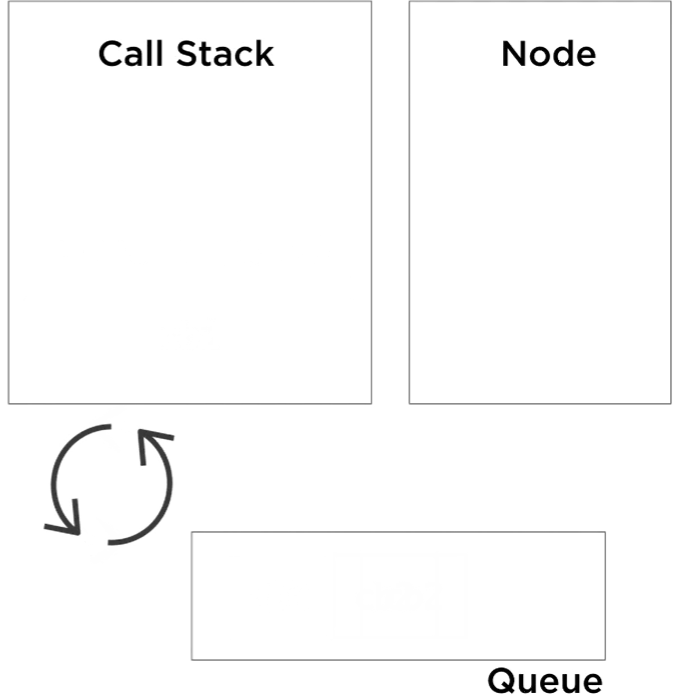
All Node APIs work with this concept. Some process will go handle a certain I/O asynchronously, keeping track of a callback, and when it’s done it will queue the callback into the event queue. Keep in mind that any slow code being executed on the stack directly will block the event loop. Similarly, if we’re not careful about the amount of events that get queued in the event queue, we can overwhelm the queue and keep both the event loop and the call stack busy. As a Node developer, these are some of the most important things to understand about blocking vs non-blocking code.
setTimeouts and process.nextTick
What happens when the timer delay is 0 milliseconds? Well, almost the same thing. Let’s walk through it. The main function pushes slowAdd(3,3), which pushes the setTimeout, which creates the timer. The timer immediately queues its callback on the queue; however, the event loop will not process that event, because the stack is not empty. So the stack continues its normal flow until we get to the second timer, which also immediately queues its callback. The stack is still not empty. After we pop all calls from the stack, the event loop picks the first callback and pushes that to the stack, and then does the same thing with the second one. Because of this loop, the timers are not really executed after 0 milliseconds, but rather after we’re done with the stack, so if there was a slow operation on the stack, those timers will have to wait. The delay we define in a timer is not a guaranteed time to execution, but rather a minimum time to execution. The timer will execute after a minimum of this delay.
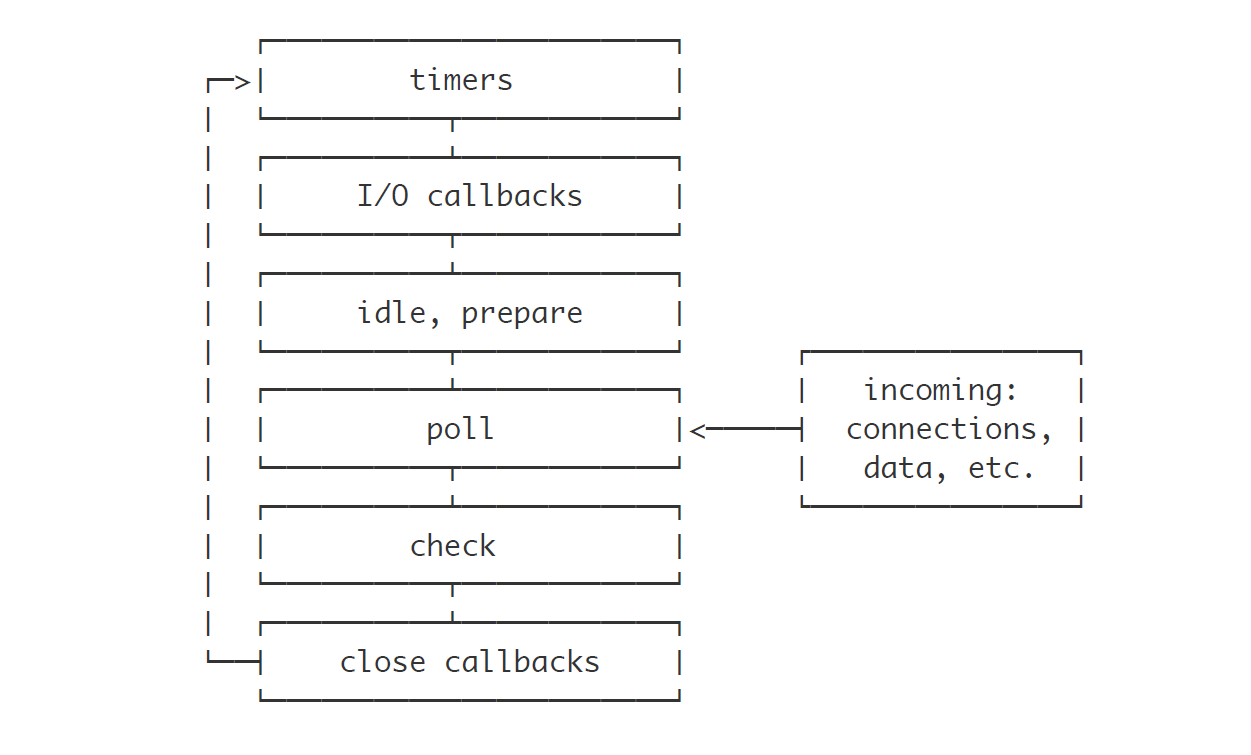
Node’s event loop has multiple phases. The timers run in one of those phases while most I/O operations run in another phase. Node has a special timer, setImmediate, which runs in a separate phase of the event loop. It’s mostly equivalent to a 0ms timer, except in some situations, setImmediate will actually take precedence over previously defined 0ms setTimeouts.
For example, below code will always display immediate before timeout, although we kick the 0ms timeout first. It’s generally recommended to always use setImmediate when you want something to get executed on the next tick of the event loop.
const fs = require('fs');
fs.readFile(__filename, () => {
setTimeout(() => {
console.log('timeout');
}, 0);
setImmediate(() => {
console.log('immediate');
});
});
// immediate
// timeout
Ironically, Node has a process. nextTick api that is very similar to setImmediate, but Node actually does not execute its callback on the next tick of the event loop, so the name here is misleading, but it’s unlikely to change. Process. nextTick is not technically part of the event loop, and it does not care about the phases of the event loop. Node processes the callbacks registered with nextTick after the current operation completes and before the event loop continues. This is both useful and dangerous, so be careful about it, especially when using process. nextTick recursively. One good example for using nextTick is to make for a standard function contract. For example, in this script, the fileSize function receives a fileName argument and a callback. It first makes sure the fileName argument is a string, and it executes the callback with an error if not. Then, it executes the asnyc function fs. stat and executes the callback with the file size. An example use of the fileSize function is here where we log the file size. Very simple.
const fs = require('fs');
function fileSize (fileName, cb) {
if (typeof fileName !== 'string') {
return cb( new TypeError('argument should be string') );
}
fs.stat(fileName, (err, stats) => {
if (err) {
return cb(err);
}
cb(null, stats.size);
});
}
// fileSize(_1, (err, size) => { // will cause error
fileSize(__filename, (err, size) => {
if (err) throw err;
console.log(`Size in KB: ${size/1024}`);
});
console.log('Hello!');
If we execute it with the current file name, it should log the size of this file. This call was async because we saw the Hello message first, which is expected because of our use of the async fs. stat function. But something is wrong with this fileSize function. Let’s trigger the validation by passing a number instead of a string here.
C:\work\webDev\advanced-nodejs>node \nextTick.js
Hello!
Size in KB: 0.4609375
>node nextTick.js
nextTick.js:20
if (err) throw err;
^
TypeError: argument should be string
at fileSize (C:\work\webDev\advanced-nodejs\2.7\nextTick.js:6:7)
at Object.<anonymous> (C:\work\webDev\advanced-nodejs\2.7\nextTick.js:19:1)
at Module._compile (internal/modules/cjs/loader.js:999:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:1027:10)
at Module.load (internal/modules/cjs/loader.js:863:32)
at Function.Module._load (internal/modules/cjs/loader.js:708:14)
at Function.executeUserEntryPoint [as runMain] (internal/modules/run_main.js:60:12)
at internal/main/run_main_module.js:17:47
Validation is a go, but the console Hello line was not executed at all in this case, because the validation code here is synchronous. So the fileSize function could be both sync and async depending on the first argument. This is usually a bad design. A function should always be either sync or async. To fix this problem, instead of directly calling the callback with an error here, we can use process. nextTick call for the callback, and with the argument of the error that we want. This way, when we actually trigger the validation, the error will happen asynchronously and the file size function is going to be always async.
// # solution using nextTick
const fs = require('fs');
function fileSize(fileName, cb) {
if (typeof fileName !== 'string') {
return process.nextTick(
cb,
new TypeError('argument should be string')
);
}
fs.stat(fileName, (err, stats) => {
if (err) {
return cb(err);
}
cb(null, stats.size);
});
}
fileSize(1, (err, size) => {
if (err) throw err;
console.log(`Size in KB: ${size/1024}`);
});
console.log('Hello!');
Summary
Hoping this module helped you understand Node’s event loop and its event-based concurrency model. We looked at V8’s call stack and how that is a record of where in the code V8 is currently executing. We looked at how slow operations affect the single-threaded call stack and looked at Node APIs like setTimeout, which does not really run at V8, but rather as a Node API that does not block the call stack. Node pushes asynchronous operations as events to its event queue, and the event loop monitors both the call stack and the event queue and de-queue callbacks from the event queue into the call stack, which gives V8 back the control to execute the content of those callbacks. We’ve also looked at two special API calls, setImmediate, which is similar to a 0ms timer, and process. nextTick, which pushes a callback immediately after the current operation and before the event loop continues. In the next post, we’ll dive deeper into Node’s event-driven architecture and see how events and listeners work with the event loop and how to use Node’s EventEmitter class.